Hadoop is a great platform for storing a lot of data, but running OLAP is usually done on smaller datasets in legacy and traditional proprietary platforms. OLAP workloads are beginning to migrate to the one data lake that is running Hadoop and Spark.
Fortunately, there are a number of Apache projects that are starting to make OLAP possible on Hadoop.
Apache Kylin
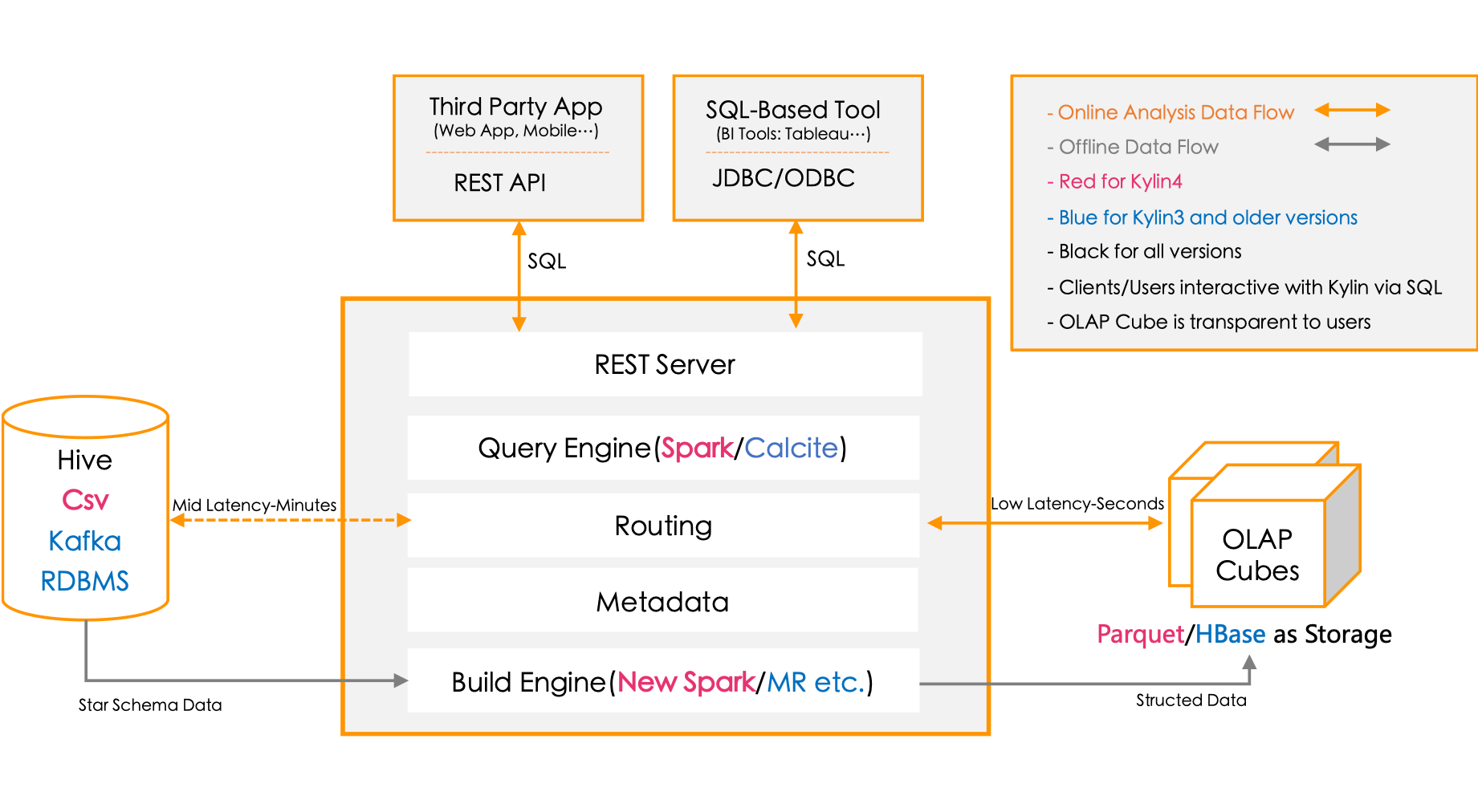
For an introduction to this interesting Hadoop project, check out this article. Apache Kylin originally from eBay, is a Distributed Analytics Engine that provides SQL and OLAP access to Hadoop datasets utilizing Hive and HBase. It can use called through SparkSQL as well making for a very useful project. This project let's you work with PowerBI, Tableau and Excel with more tool support coming soon. You can do MOLAP cubes and support many users with fast queries over billions of rows. Apache Kylin provides JDBC and ODBC drivers.
Check our Post with demo online and detailed information
An interesting talk on Mondrian, MDX and Apache Kylin, points to big things in OLAP. Yet another project using the excellent Apache Calcite. I would recommend giving this project a try and see if it meets your needs. It is one of the best options out there. It is currently not part of the Big Hadoop Three's supported stacks.
Druid
Druid is another very strong offering in fast SQL OLAP solutions on Hadoop with support growing rapidly. The documentation for this project is excellent and makes it easy for OLAP-oriented DBAs, data architects, data engineers and data focused programmers to get started with this interesting Big Data project. Druid provides sub-second OLAP Queries with column orientation and inverted indexes enabling multi-dimensional filtering and scanning to allow for aggregating and filtering data. Again, not officially part of the Big Hadoop Three's supported stacks. I recommend downloading and installing this project and giving it a test run. Airbnb and Alibaba are users of Druid. And the secret word for Druid; Apache Calcite. This project seems to be everywhere and you will find it here as well. Apache Lens
Apache Lens provides a unified analytics interface to Hadoop. It is pretty quick to install, works with Hive, JDBC and OLAP Cubes. There is an Apache Zeppelin interface for Apache Lens which is good. I don't hear a lot about this one, but again it seems interesting.
Other Options To Investigate:
- SnappyData (Strong SQL, In-Memory Speed, and GemfireXD history)
- Apache HAWQ (Strong SQL support and Greenplum history)
- Splice Machine (Now Open Source)
- Hive LLAP is moving into OLAP, SQL 2011 support is growing and so is performance.
- Apache Phoenix may be able to do basic OLAP with some help from Saiku or STPivot. I really like Phoenix and it has the performance and power to back up a lot of data through queries and concurrency. It is lacking a lot of the OLAP specific queries that some tools and users will most likely need. I am thinking that Apache Calcite and Phoenix will eventually make this a great OLAP tools.