Muy interesante esta reflexión de Tristan Elosegui, de hace ya un par de años, pero que mantiene toda su vigencia. Abajo os indicamos los puntos principales que detalla:
En TodoBI, hablamos mucho de Dashboards (ver posts), de los que os destacamos:
- 12 aplicaciones gratuitas para crear Dashboards
- Tutorial de Creación de Cuadros de Mando Open Source
- Ejemplos Dashboards
- Cuadro de Mando Integral (Scorecard)
Según Tristán, las empresas tienen gran cantidad de datos a su alcance, pero no son capaces de poner orden entre tanto caos y como consecuencia, no tienen una visión clara de la situación.
El ruido es mayor que la ‘señal’
El volumen de datos y la velocidad con la que se generan, provocan más ruido que señal.Esta situación lleva a las empresas a la toma de decisiones sin los datos necesarios o a la parálisis post-análisis en lugar de facilitar la acción (toma de decisiones).
Los datos llegan desde diferentes fuentes, en diferentes formatos, desde diferentes herramientas,… y todos acaban en informes, que intentan integrar en un dashboard que les ayude a tomar decisiones.
¿Por qué teniendo tantos datos las empresas no son capaces de tomar decisiones estratégicas?
Tener muchos datos no siempre significa tener mejor visión sobre la situación. Seguro que más de uno de los que estáis leyendo este post, os sentís identificados.Las empresas toman decisiones en base a datos todos los días (y sin datos también), el problema es que estas decisiones son tácticas ya que se toman tipo ‘silo’ (por áreas).
Para poder tomar decisiones que optimicen la estrategia global de la empresa necesitamos:
- Tener los datos necesarios, ni más ni menos, para tomarlas (la foto más completa posible del contexto) y
- ser capaces de entender los datos,para transformarlos eninformación y a continuación en conocimiento.
Falta de contexto
El motivo principal para no tomar decisiones, es que los datos representados en el dashboard no sean relevantes, no sean accionables.Esto ocurre cuando no hemos definido correctamente el dashboard (los pasos correctos están definidos en el modelo de madurez de la analítica digital). Los errores más comunes suelen ser:
- Objetivos y KPIs mal definidos: si el punto de partida esta mal definido, todo lo que venga detrás nos llevará a error. Y por supuesto, el contexto será del todo equivocado.
- Datos irrelevantes o no accionables: bien por una mala definición de objetivos y de las KPIs que nos ayudan a controlarlos o simplemente porque hemos seleccionado mal los datos, llegamos a un dashboard lleno de números y gráficas, que no nos permite tomar decisiones.Bien porque no muestra los datos con el área de responsabilidad de la persona que toma las decisiones, o simplemente porque son datos no accionables. En cualquiera de los dos casos el resultado es el mismo.
- Datos incompletos: es el otro extremo del caso anterior. Nos faltan los datos necesarios para tomar decisiones.
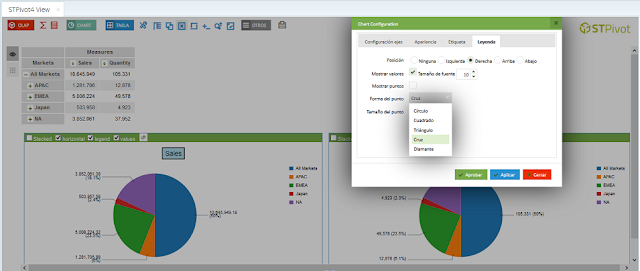
Visualización de datos
El segundo gran problema es que la persona que tiene que tomar las decisiones no entienda los datos.Al igual que tenemos que mostrar a cada stakeholder los datos que son relevantes para su trabajo (caso anterior), tenemos que adaptar el lenguaje y la visualización, para que el decisor entienda lo que está viendo.
Así que, para que un dashboard estratégico funcione debes empezar por tener definir bien los objetivos y KPIs, trabajar la calidad del dato, que estos datos te estén contando lo que te interesa y que integren datos de las diferentes fuentes que manejas.
No te saltes ninguna fase del modelo de madurez de la analítica digital, porque sino te puedes encontrar con los problemas que hemos visto en este post.
Ver Articulo completo