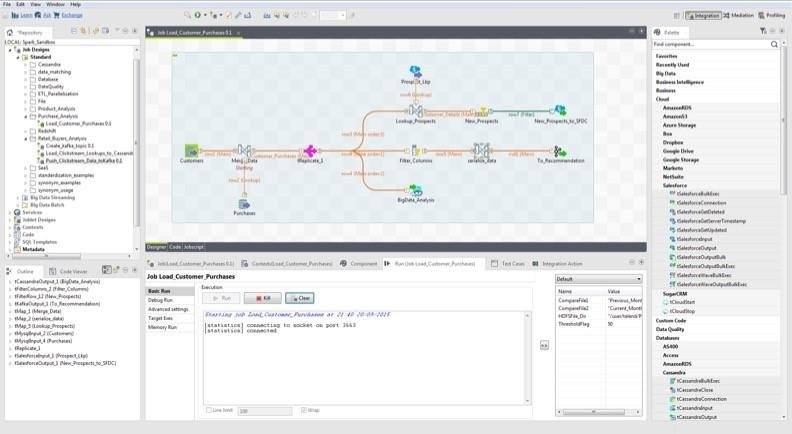
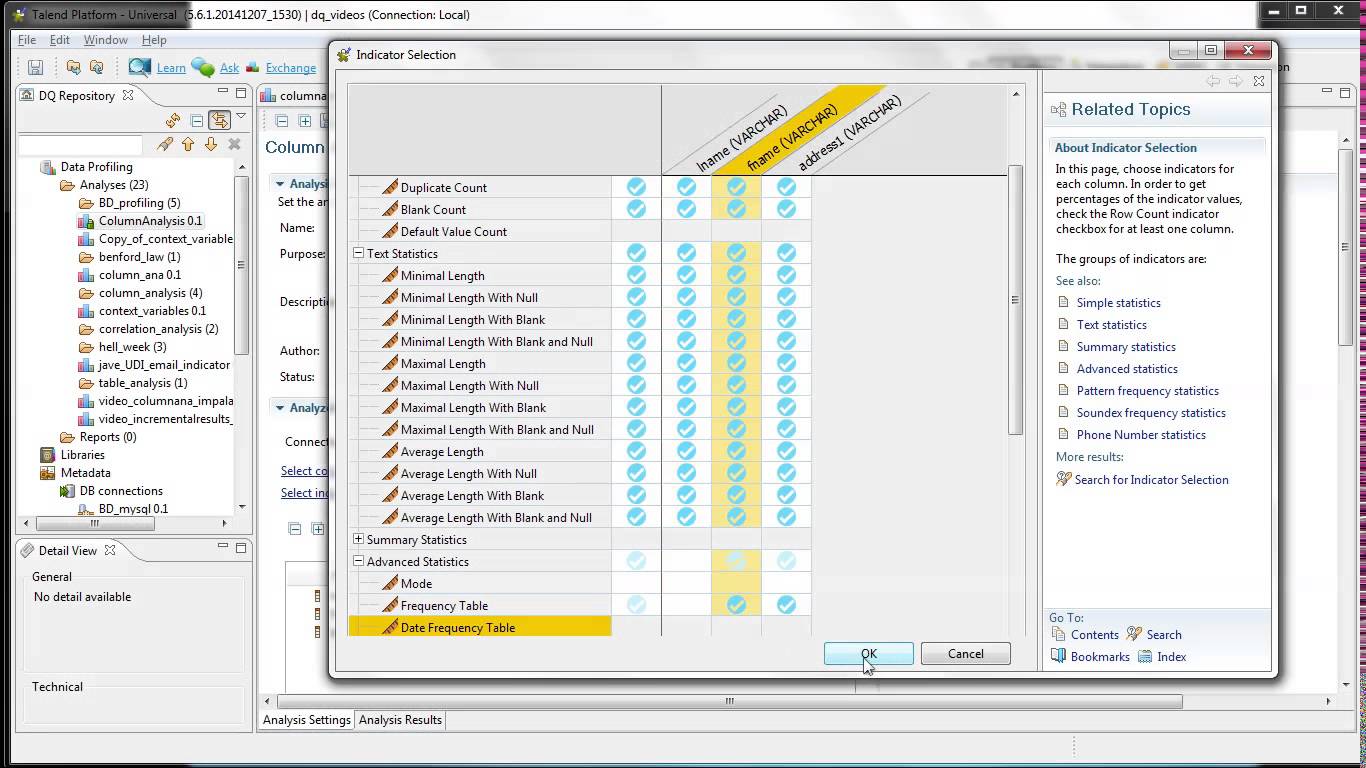
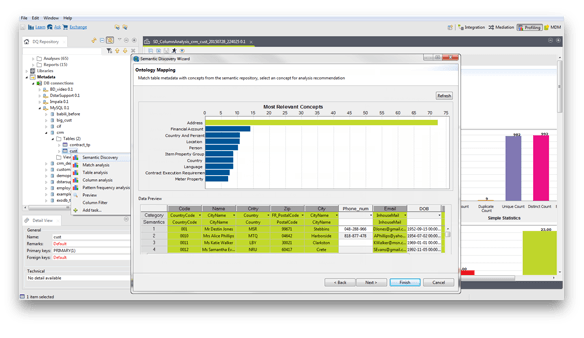
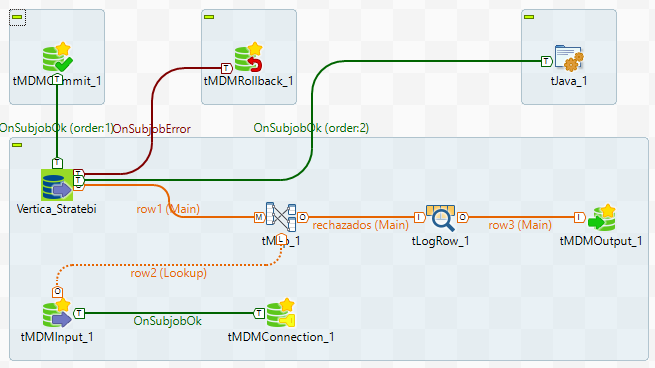
Esto limita las posibilidades para llevar tu Business Intelligence al cloud o tener un BI Corporativo con las ventajas de ambos modelos.
Os vamos a contar 6 motivos por los que puedes llevar tu BI a la nube y uno por el que no:
1. Reducción de Costes
Si te adaptas a las características de las soluciones BI que te proponen muchas empresas, con los límites, niveles premium, etc... puedes conseguir unos precios mensuales/anuales muy buenos por usuario
2. Aumentar los recursos, según se necesiten
En negocios y sectores en los que puedes tener variaciones en las concurrencias de uso muy altas, incrementos de volumenes de datos en determinados periodos, análisis real-time puntuales, etc... la posibilidad de asignar más recursos de forma fléxible es una gran ventaja
3. Desarrollos más ágiles
El no tener que depender de las áreas de sistemas, o de la disponibilidad de hardware en tiempo y capacidad de forma adecuada, hace que los desarrollos de proyectos e implementación se puedan demorar en gran manera
4. Entornos compatibles
Llevar tu BI a la nube te puede permitir tener algunos componentes y conectores desplegados de forma nativa, referentes a redes sociales, machine learning, bases de datos, etc...
5. Seguridad y Disponibilidad
Aunque no tener los datos en tus propias máquinas puede darte qué pensar, lo cierto, es que muchas compañías, para gran cantidad de información tienen más seguridad de no perderla o de tener brechas si confían en un entorno en la nube que en sus organizaciones internas, de las que no confían tanto
6. Acceso desde cualquier lugar y momento
Cada vez más, desde que se produjo la democratización del Business Intelligence y más usuarios, analistas, etc... hacen uso de los sistemas BI desde todo tipo de redes, accesos, dispositivos móviles... los entornos en la nube pueden garantizar un acceso común y similar para cada uno de ellos

Y por qué no mover a la nube?
Todas esas ventajas tienen el inconveniente de que si quieres desplegar el BI 'on premise', en tus propios entornos, controlando los datos sensibles y accesos, te topas con que el coste de las correspondientes licencias se dispara hasta niveles increíbles.
Es el 'peaje' a pagar, por salirte del camino marcado en la nube por los grandes proveedores.
Salvo que.... y esa es la gran ventaja del modelo open source o sin coste de licencias, que se está extendiendo, que puedas desplegarlo 'on premise' o en una 'nube privada', controlada por tí, con todas las ventajas anteriores, más la de ahorro de costes.
Confía en las soluciones BI Open Source o sin coste de licencias y que tener tu BI en la nube o 'on premise' no sea un problema